13 类集合框架
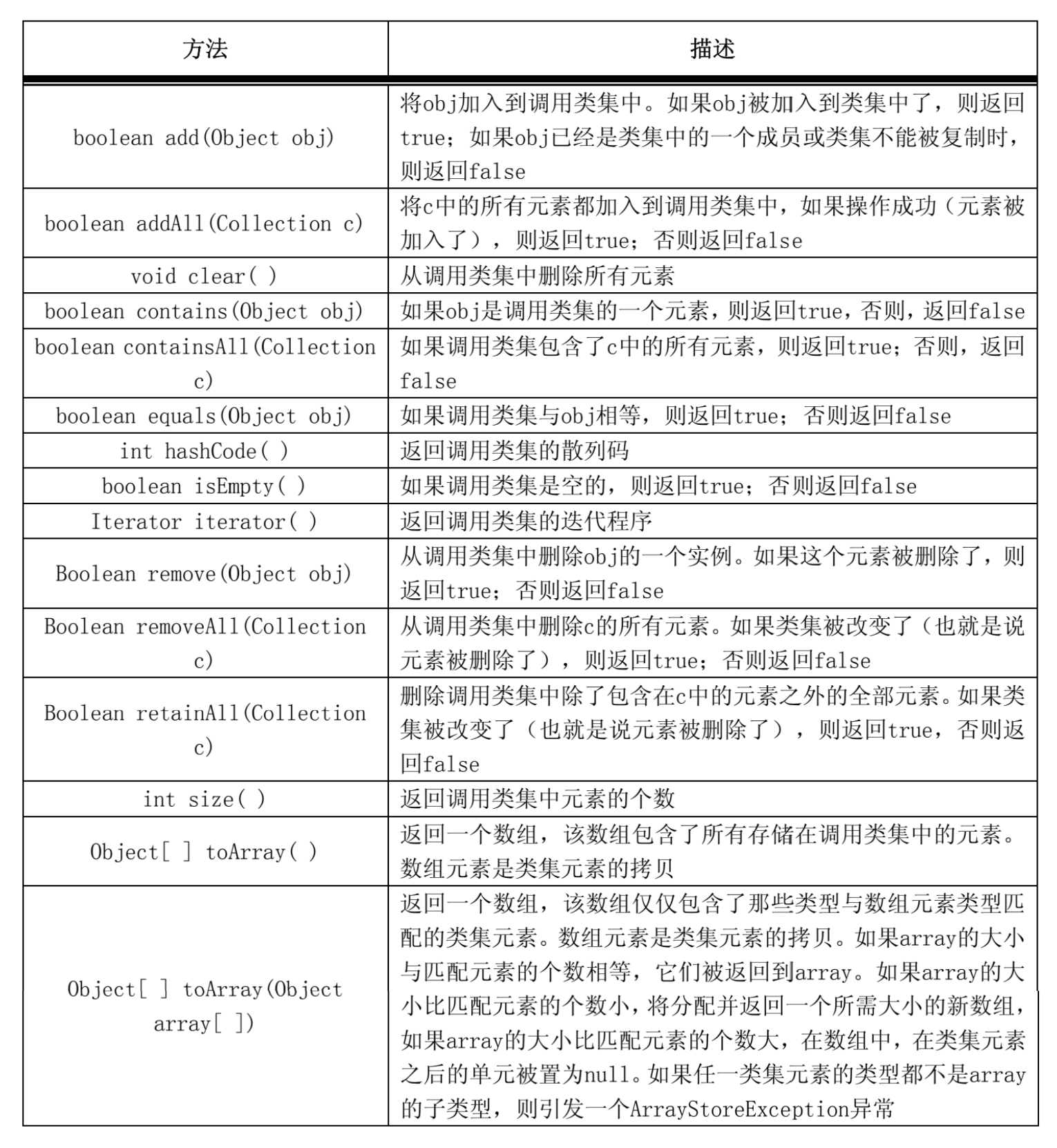
Collection定义的方法:
单列集合+双列集合
Collection接口有两个子接口 list Set实现的子类均为单列集合 Map接口实现的子类为双列结合(K_V )
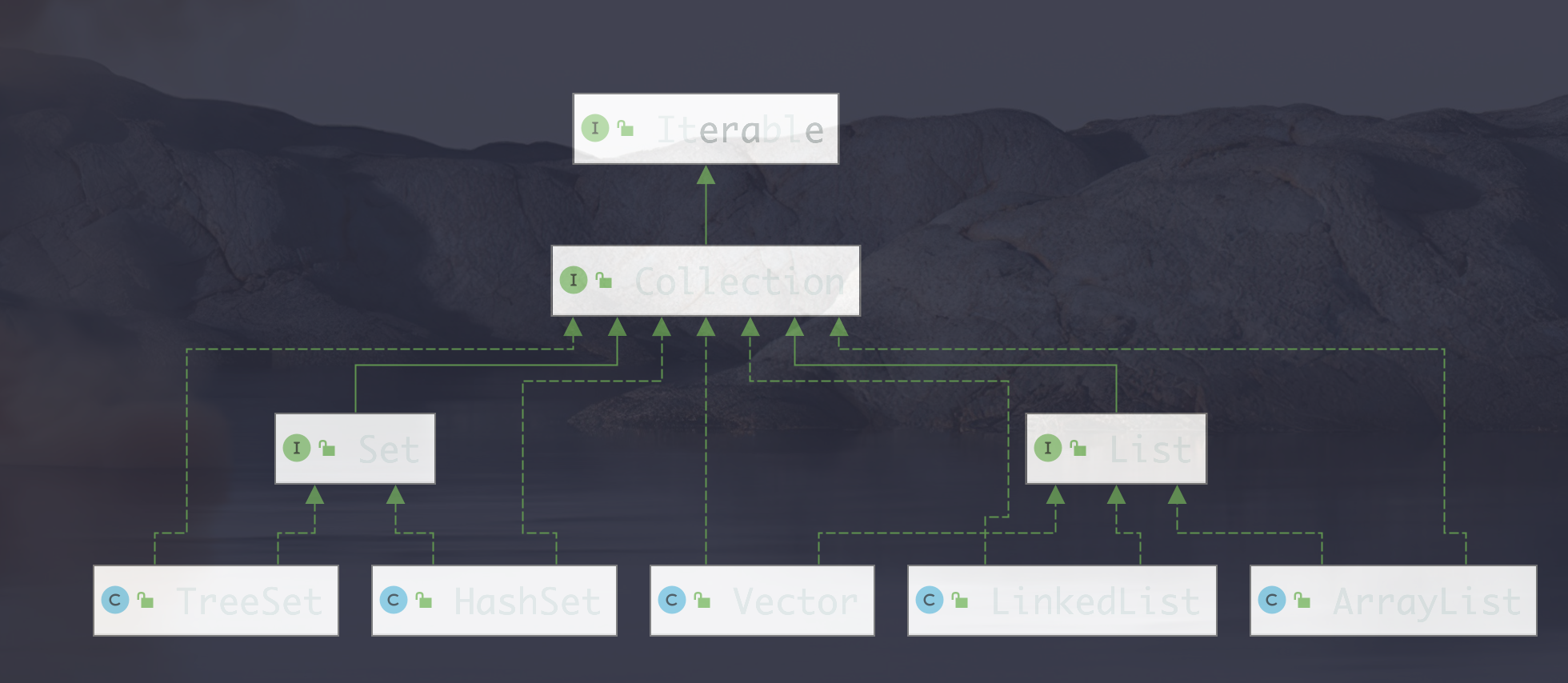
13.01 Collection接口
-
常用方法
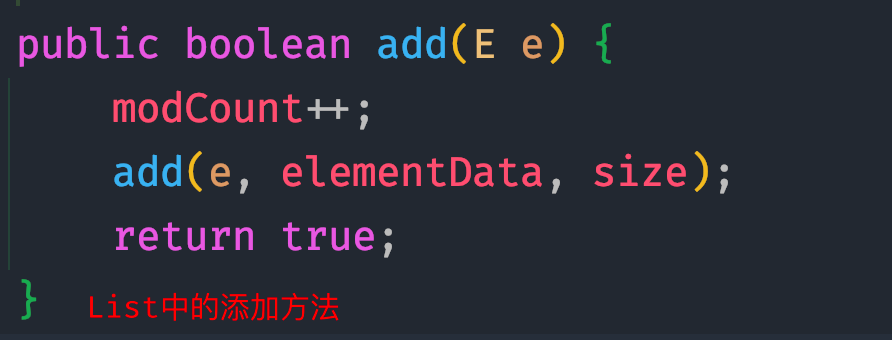
- add/addAll
- remove/clear/removeAll
- contains/containsAll
- size
- isEmpty
-
遍历:
-
迭代器——>Iterator对象; 所有实现Collection接口均实现

-
13.02 List接口
List特点:
- 元素有序(添加和取出顺序 ) 可重复
- 支持索引 从0开始
实现List接口有: ArrayList LinkedList Vector Stack etc.
List接口常用方法: 常见8种
// index位置插ele List长度自动+1
void add(int index, Object ele);
//index位置开始将eles中所有元素加入
boolean addAll(int index, Collection eles);
// 获取index位置元素
Object get(int index);
// 返回object在集合中首次出现位置
int indexOf(Object obj);
// 返回obj在集合中末次出现位置
int lastIndexOf(Object obj);
// 移除index位置元素并返回该元素
Object remove(int index);
// 替换index位置元素为ele——>也可用于交换
Object set(int index, Object ele);
// 返回从fromIndex到toIndex位置的子集合 前闭后开[forIndex,toIndex)
List subList(int formIndex, int toIndex);
set可用于交换 注意先后访问的顺序
List常见遍历方式:
// 迭代器遍历
Iterator ite = collection.iterator();
while(ite.hasNext()) {
Object next - ite.next();
}
// foreach遍历
for(Object o : Collection) {
}
// 普通fori
for (int i = 0; i < Collection.size(); i++) {
Object o = Collection.get(i);
}
ArrayList注意事项⚠️
-
可以加入多个null
-
是由数组底层实现
-
线程不安全——>没有
synchronized可以等同于Vector (线程安全)
底层源码阅读 注意IDEA默认debug不显示null的扩容内容
-
维护
Object类型数组elecmentDatatransient object[] elementData表示为瞬时 该属性不会被序列化
-
创建
ArrayList对象时:- 无参构造器——>初始化的elementData容量为0, 第一次添加扩容elementData为10, 再次扩容则为1.5倍(0_10_15_22)
- ArrayList(int) 指定大小的构造器——>elementData容量为制定大小,扩容则直接扩为1.5倍
扩容:
// 右移一位 ——> /2int newCapacity = oldCapacity + (oldCapacity >> 1);// 使用Arrays.copyOf(nums,length)来对底层数组elementData扩容return elementData = Arrays.copyOf(elementData, newCapacity);// Arrays.copyOf()超出nums的len范围用null来填充无参构造器:
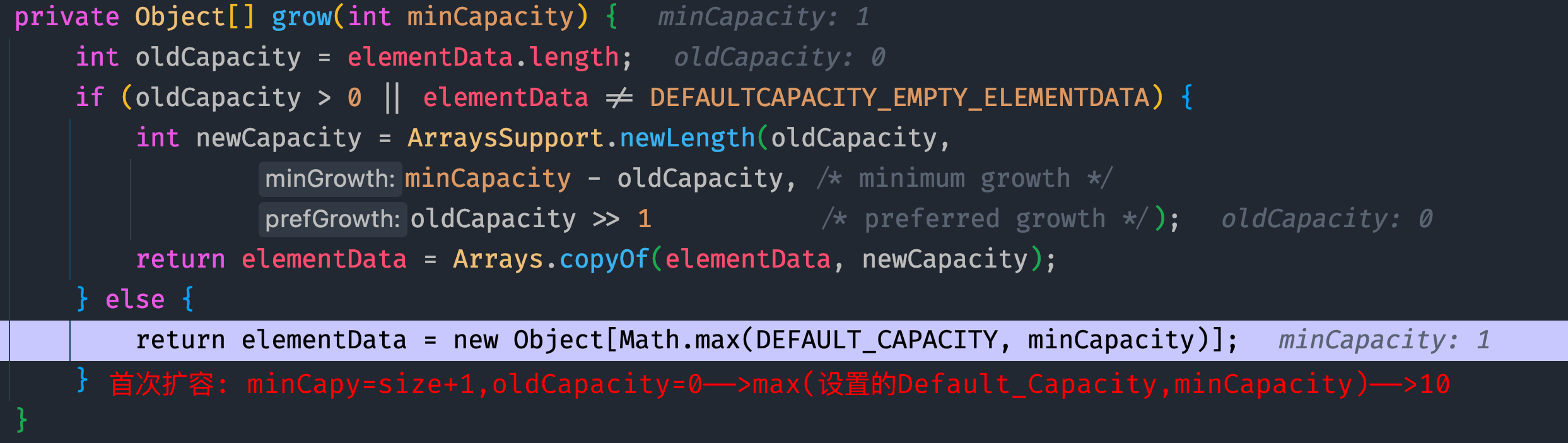
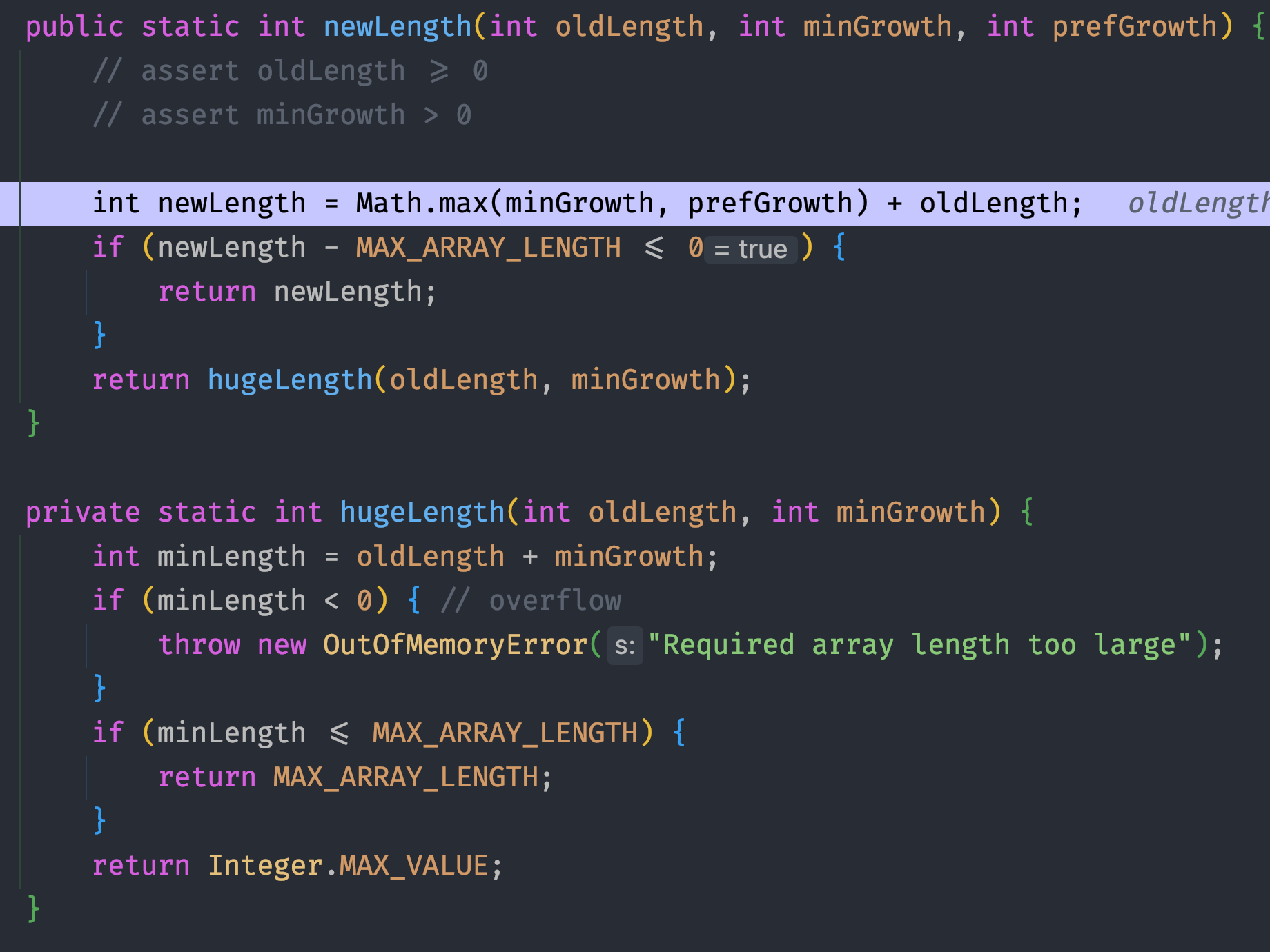
ArraysSupport.newLength方法用于获取newCapacity
Vector底层结构&源码剖析
-
底层同样是对象数组
protected Object[] elementData -
线程同步安全 操作方法带有
synchronized无参构造: 默认10initalCapacity 再按照2倍扩容
指定大小: 每次2倍扩容
LinkedList源码和结构

- 底层双向链表、队列——>插入、删除效率高
- 维护两个属性first last 分别指向首尾结点
- 每个节点Node维护prev next item三个属性
- 双向链表的插入——> waitInsert.next=prevNode; waitInsert.pre=nextNode; prevNode.next=waitInsert; nextNode.pre=waitInsert;
- 元素任意(可以重复) 包括null
- 线程不安全 没有实现同步
LinkedListCRUD
linkedList.add(item)——>使用linkLast(e)函数(将添加的节点挂入原链表的最后)
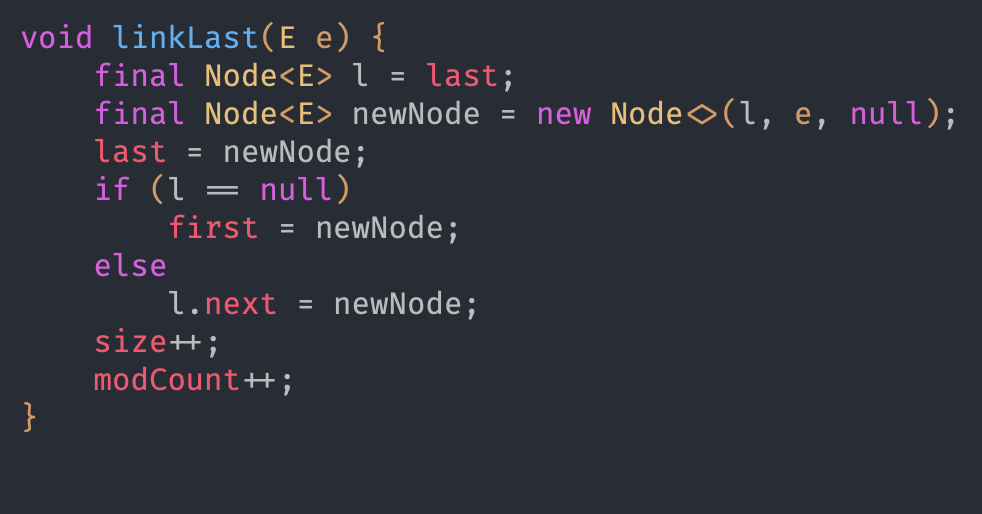
Explain To linkLast(E e)
初始last=null——>第一个节点时 first last newNode均指向节点newNode——>再插入则 l=last last=newNode 将newNode的prev指向l 即原先的last(上一个节点位置) 同时将last指向newNode 设为双向链表的尾指针——>l!=null 再将上一个节点的next指针指向newNode 同时更新size/modCount 完成两个节点之间的链接
linkedList.remove(int index)——>首先使用node(index)函数找到index下标的结点并返回该节点——>调用unlink(Node

Explain To node(index)
判断下标index在整个链表的前部还是后部——>⚠️后部i=size-1;i>index;i-- 判断

Explain To unlink(Node<E> x)
暂存待删结点x的前后结点
prev next——>移动x的前一结点的next指向x的下一结点prev.next=next 移动x的下一结点的prev指向x的上一结点next.prev=prev ——>同时将x的prev和next均置空(help GC) ——>最后item置空并链表size-1
ArrayList && LinkedList Compare
ArrayList——>增查
LinkedList——删改
均为线程不安全
13.03 Set
Feature:
- 无序(添加与取出的顺序不一致) 没有 index 索引
- 取出的顺序一次设定即被固定
- 无重复元素——>最多包含一个 null 多个重复数字后者不会被添加
set接口实现的类:HashSet、TreeSet、LinkedHashSet、etc.
Mathods:
- 是 Collection 的子接口——>常用方法一致
- 遍历:迭代器 foeeach 不可 index 索引
HashSet
instructions:
-
实现 Set 接口
-
本质上是
HashMap ——
——HashMap底层是数组+链表+红黑树- 在数组的某个index 位置存储链表(数据存储的高效)
- index 上存储的链表长度>8(TreeIfy_Threshold)并且数组长度>64(Min_TreeIfy_Capacity) ————>转化为树
-
可存放 null 但仅可有一个 元素不可重复
- 注意元素重复与否与 JVM 内存相关——>常量池、栈内存
- toString 没有重写则输出为引用的地址 重写则为内容
- new String(“**”)——>先在常量池中查找有没有已经存在的 str
-
不保证元素有序,取决于 Hash 后在确定索引
HashSet add Method
- 添加元素时——>得到元素的 hash 值再转化——>索引值(存储位置)
- 存储数据表 tables——>是否已经存放(没有直接加入、有则下步比较 )
- 有调用 equal 比较——>不相同再加入到最后
hash 值计算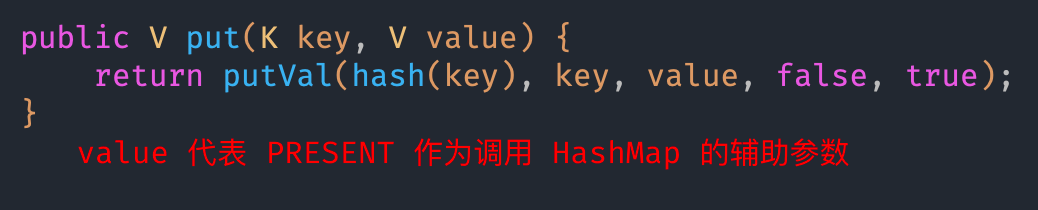
第一次 add
依据 hash 计算出的 key 应该存档于 table 的位置,并赋值给辅助变量 p(p 指向索引的结点)
再判断 p 是否为空——>空(对应的插入位置无元素)则将 key新建 Node 并存入 tab[i] (hash key value=present next)——>判断 size 与 threshold(0.75*16) 扩容与否 再返回 null 则表示插入成功
add 所插入的位置非空——>
p.hash==hash && ((k=p.key)==key)||(key!=null&&key.equals(k)) hash value equals 三重比较确保两者不相同
返回 oldValue 非空则插入式失败
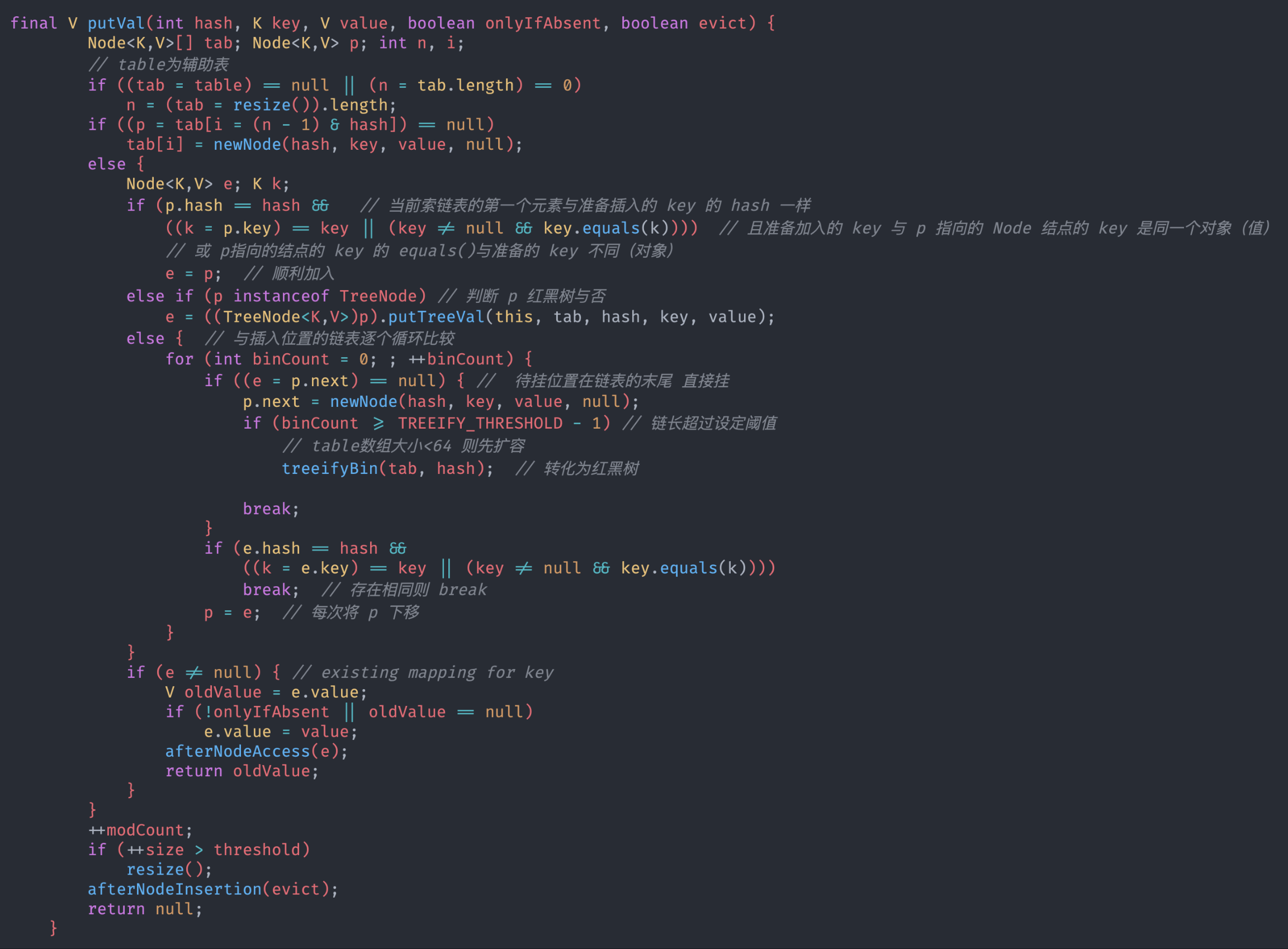
HashSet 扩容机制
-
底层
HashMap第一次添加时table 数组扩容到 16,阈值threshold为 16*0.75加载因子(loadFactor)=12 -
table 数组扩容为* 2=32 新的临界值(threshold)为 0.75*32=24扩容是使用左移<<1实现 * 2
-
链表元素个数达到
TreeIfy_Threshold(8)且 table 数组大小>=Min_Treeify_Capacity则转化为红黑树,否则仍然是扩容数组
使用重写 class 的 hashcode 方法 返回同一个 hashcode 使得插入在 map 的同一个数组 index 上的链表内 链表长度超过 8 后会使 table 扩容 <<1 表长+1 扩容为 32表长再+1 到 10 再扩容 64 若在添加元素则树化 treeifyBin 方法
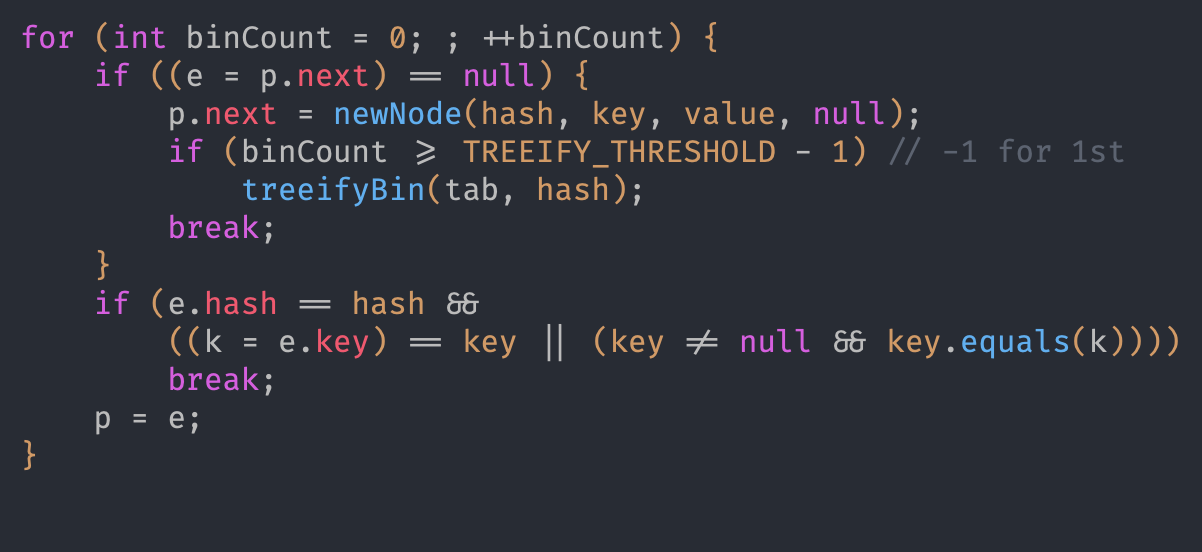
直到走到链表末尾进行且 binCount>=8-1=7(从 0 开始)则调用treeifyBin方法树化 传入 table 和 hash 参数
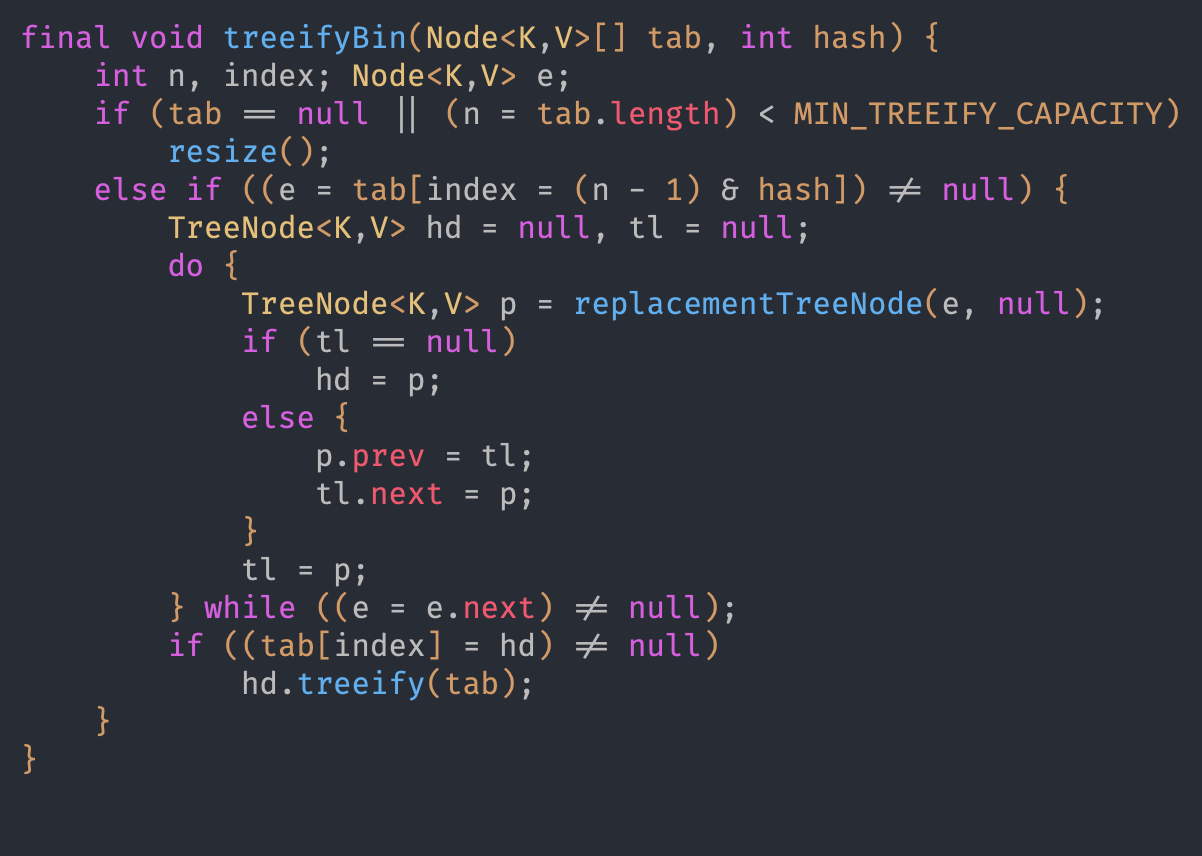
Min_TreeIfy_Capacity=64
tab[index=(n-1)&hash] 找到数组储存数据的位置并将e 指向这个引用
LinkedHashSet
Features:
- 属于 HashSet 的子类;
- 底层是
LinkedHashMap,维护了数组+双向链表;- 依据元素的
hashcode决定元素的存储位置,同时用链表维护元素的次序(图),使得元素看起来插入顺序保存;- 不允许重复元素;
Explain
- 维护 hash 表和双向链表(属性有 head 和 tail) 使得每次后续插入的元素连接在最后 有序
- 每个节点有 prev 和 next 属性 before after
- 添加元素时,先求 hash值再求索引,从而确定元素在 hashtable 的位置——>再添加进入双向链表
- 遍历顺序保证与插入顺序一致
-
底层维护
LinkedeHashMap结构 ——>是HashMap的子类 -
首次初始化为 16(size)结点类型为
LinkedHashMao$Entry——>数组是HashMap$Node[]存放的元素是LinkedHashMap$Entry即为多态 继承父类的属性
要求 hashcode 和 equal 均相同才无法加入,对于非基本数据类型需要重写两个方法 equal 和 hashcode
TreeSet
可以排序
使用无参构造器创建TreeSet 无序
有参可以使用Comparator 接口——>传入比较器 匿名内部类
构造器将传入的比较器对象comparator赋给 TreeSet 底层的 TreeMap 的属性 comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)
: comparator.compare((K)k1, (K)k2);
}
在 TreeSet 的 add 方法会调用
private V put(K key, V value, boolean replaceOld) {
Entry<K,V> t = root;
if (t == null) {
addEntryToEmptyMap(key, value);
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
// 调用自定的 compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else {
// 两个值相等时候即返回 oldVaule 无法添加
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
} else {
Objects.requireNonNull(key);
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
// 这里的循环逐个比较则一旦出现相应的就 return了
// 即==时候无法被加入(==为自定的规则)
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else {
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
}
addEntry(key, value, parent, cmp < 0);
return null;
}
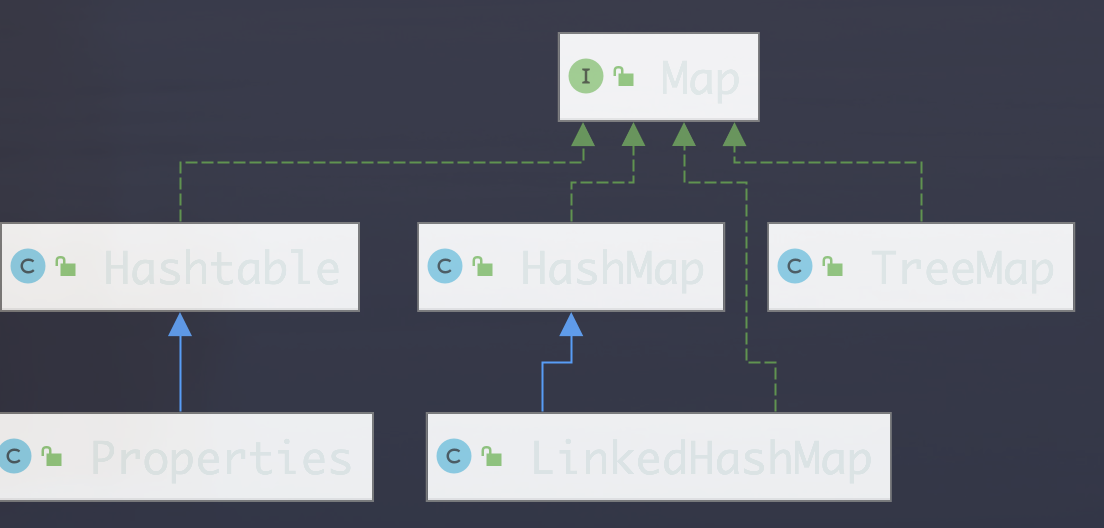
13.04 Map
该接口子类具有的特点:
Features:
- Map 和 collection 并列,用于保存具有映射关系的 Key-value 之间为单项一对一的关系
- Key Value 可以是任何引用类型的数据 object,会被封装到 HashMap$Node 内部类,Node 实现Entry 接口,即一对 K-V 就是一个 Entry
- 使用 EntrySet 内部类,定义的类型是 Entry 实际上存放是 HashMap$Node 因为 Node implement Map.Entry 接口——>接口的多态
- EntrySet 方便遍历——>提供了 getKey getValue 方法
- Key 可为 null 仅一个但不可重复(),value 可以重复并可为 null
Node——>Entry——>EntrySet
Properties:
继承自HashTable 并且适用于 Properties文件类型导入加载数据到 Properities 类对象读取和修改
读取配置文件时候常用
集合选择
- 存储类型
- 单列对象:
Collection接口- 允许重复:List
- 增删:LinkedList——>底层双向链表
- 改查:ArrayList——>底层维护 Object 可变数组
- 不允许重复:Set
- 无序:HashSet——>底层 HashMap 维护哈希表(数组+链表+红黑树)
- 排序:TreeSet
- 插入和取出循序一致:LinkedHashSet——>数组+双向链表
- 允许重复:List
- 双列键值对:Map
- 键无序:HashMap——>哈希表
- 键排序:TreeMap
- 键插入和取出顺序一致:LinkedHashMap
- 读取配置文件:Properties